Leading brands consistently invest serious cash into understanding customer feelings. Feedback like I love my new shoes, but hated how long it took them to ship holds the key to understanding what pain points or positive moments make or break a user’s experience. Even reviews that look overall negative or positive may be hiding more mixed comments that a human eye might miss. And for every negative brand impression, it may take quite a few subsequent positive impressions to change the customer’s opinion.
AI-powered sentiment analysis isn’t new, but without a dedicated team of coders and data scientists, it’s never been able to offer more than surface-level insights. Until now.
Our team is excited to introduce Concept-Level Sentiment in Luminoso Daylight. With this new offering, our users can now quickly and accurately discover positive and negative components of their offerings, at a more powerful, nuanced level than ever before.
The old way: document-level lexicons
In the past, typical approaches to sentiment analysis used a lexicon, or word list, for every language. This approach requires creating and curating word lists, and manually assigning relative intensity to each word. Positive words like love could be assigned a score such as +5, with like being +2, and dislike being -3 . This approach can produce some impactful sentiment results without sophisticated AI modeling.
But the drawbacks to this approach are significant. Lexicons ignore the context in language, only examining words in isolation. Lexicon lists often contain very basic words, like amazing or terrible, which don’t offer the necessary nuance for business-critical insights about emotions. To go beyond the surface level in any particular industry or organization, organizations would need experts to outline domain-specific lists. And, multilingual sentiment analysis requires a separate word list for every language. Every list also requires scrutiny for manually-introduced bias – for example, assigning static sentiment to the adjectives democrat or republican would be highly charged in today’s political climate in the US. Word lists require frequent maintenance as new words become trendy: for example, the adjective dewy is now used to describe a positive makeup look.
Typically, lexicons are paired with document-level analysis. Product reviews or survey responses are classified entirely as positive, negative, or neutral based on the combination of lexicon words they include. Analytically, this is like pairing a hammer with another hammer – both are blunt instruments that work to complete the same end goal in the exact same way.
Now: detect sentiment as well as a human
Now, state-of-the-art sentiment science leverages the power of multilingual deep learning models. One way to imagine a deep learning model is like a 3D printer, which uses digital specifications to layer together materials and build a complex 3D object. Likewise, a deep learning
model reads and rereads a piece of text, each time paying attention to different aspects, to construct a complex representation of a word or phrase in its context.Take, for example, this product review about a banking app:
I used to love this app but now they have ‘improved’ it, it won’t let me deposit checks. It just freezes my phone. I have uninstalled and reinstalled the app and it still doesn’t work. Please fix this ASAP and then stop trying to ‘improve’ things.
A document-level lexicon model would scan through this document, and identify love and improve as positive:
I used to love this app but now they have ‘improved’ it, it won’t let me deposit checks. It just freezes my phone. I have uninstalled and reinstalled the app and it still doesn’t work. Please fix this ASAP and then stop trying to ‘improve’ things.
Since the lexicon model didn’t find highly negative sentiment in this document, like terrible or bad, it marks the document as positive. But humans know that the AI has missed the mark – both at the document-level, and at the concept-level. Clearly, used to modifies love, and stop trying modifies improve – and neither of these words were positive. The user is nostalgic for what the app once was, not what it has become.
I used to love this app but now they have ‘improved’ it, it won’t let me deposit checks. It just freezes my phone. I have uninstalled and reinstalled the app and it still doesn’t work. Please fix this ASAP and then stop trying to ‘improve’ things.
A concept-level deep learning model would scan through a document multiple times, paying attention to a variety of contextual elements about the app as it goes. For example, it would realize that while the word app was only expressed twice, the pronouns it and this also reference it. The model intelligently updates its interpretation of app based on sentiment expressed around it and this:
I used to love this app but now they have ‘improved’ it, it won’t let me deposit checks. It just freezes my phone. I have uninstalled and reinstalled the app and it still doesn’t work. Please fix this ASAP and then stop trying to ‘improve’ things.
This approach allows the tool to correctly identify true sentiment, even in unstructured text samples that skew largely positive or negative because of leading questions. Or, to make more accurate determinations for industries with highly specialized language. For example, depending on context, the word cheap could be positive, negative, or neutral:
These bags are great. They are roomy, wipe clean, have a zipper, are made of recycled material, and they are cheap. Love them.
Very low quality materials and this watch was his birthday present and I felt horrible and cheap because it broke in half the minute he tried to put it on.
I bought this watch to use as a cheap timer at summer camp.
The same could be true with concepts like blood in healthcare, or challenge in human resources. Thanks to the model’s attention to context, it takes into account not only how the word is used in the language as a whole, but specifically how it’s being used in your dataset.
Using Concept-Level Sentiment in Luminoso Daylight
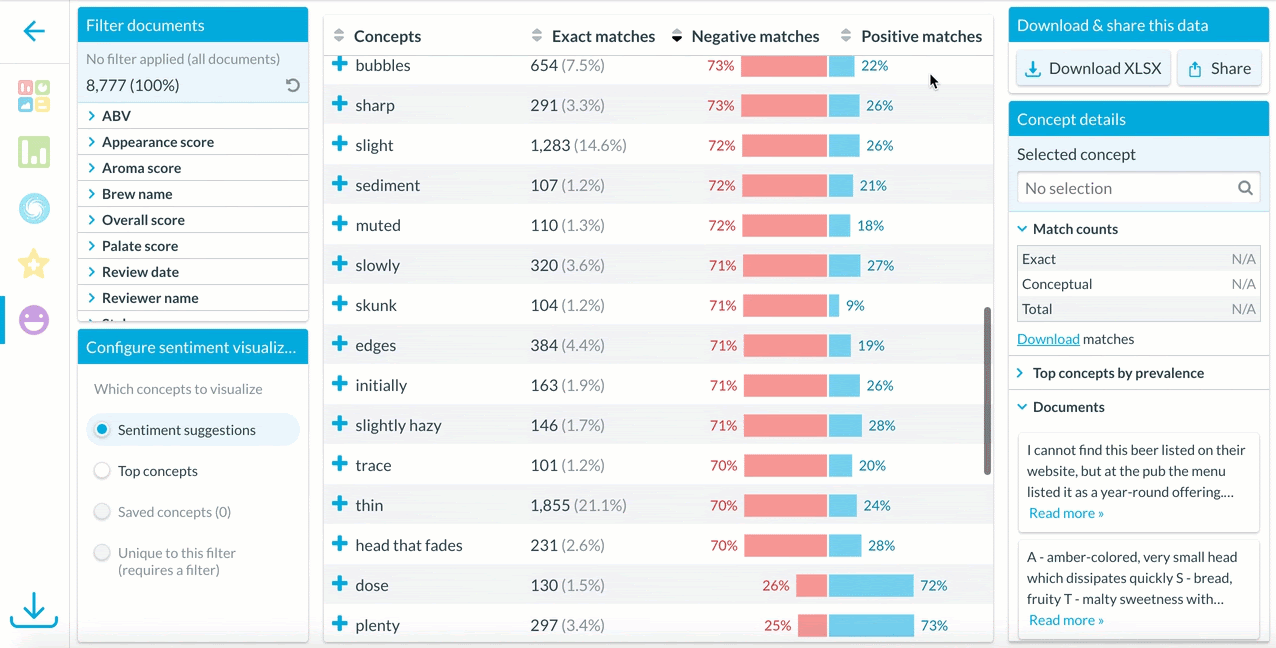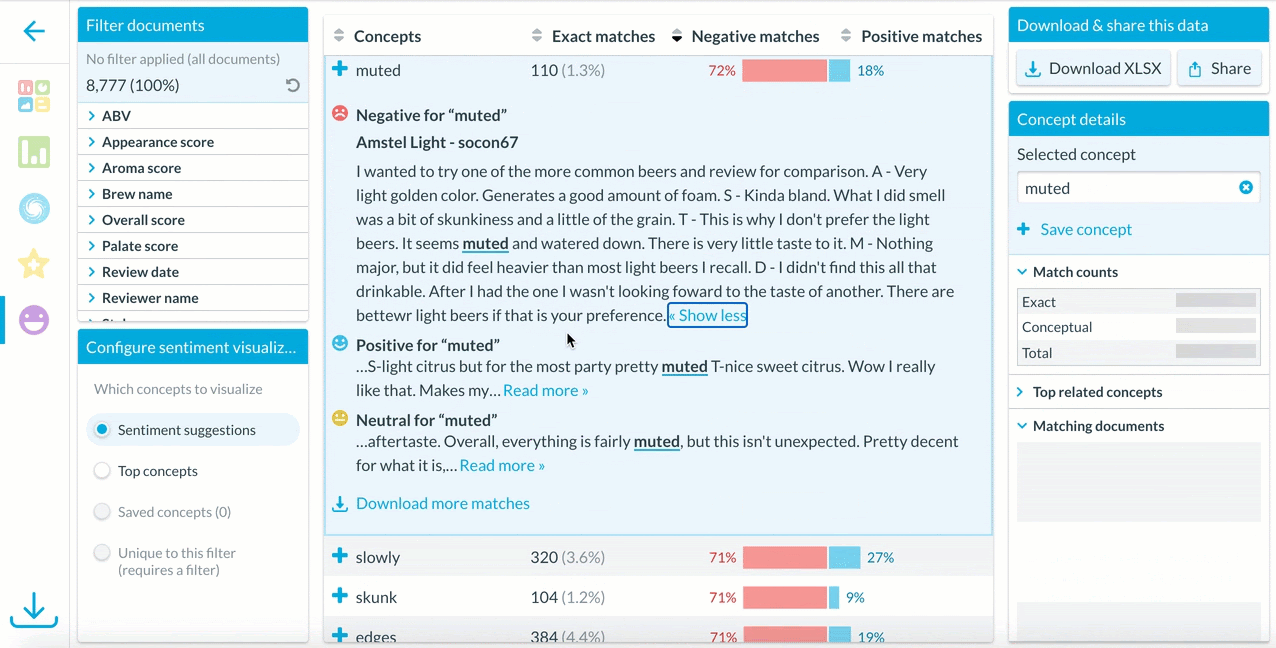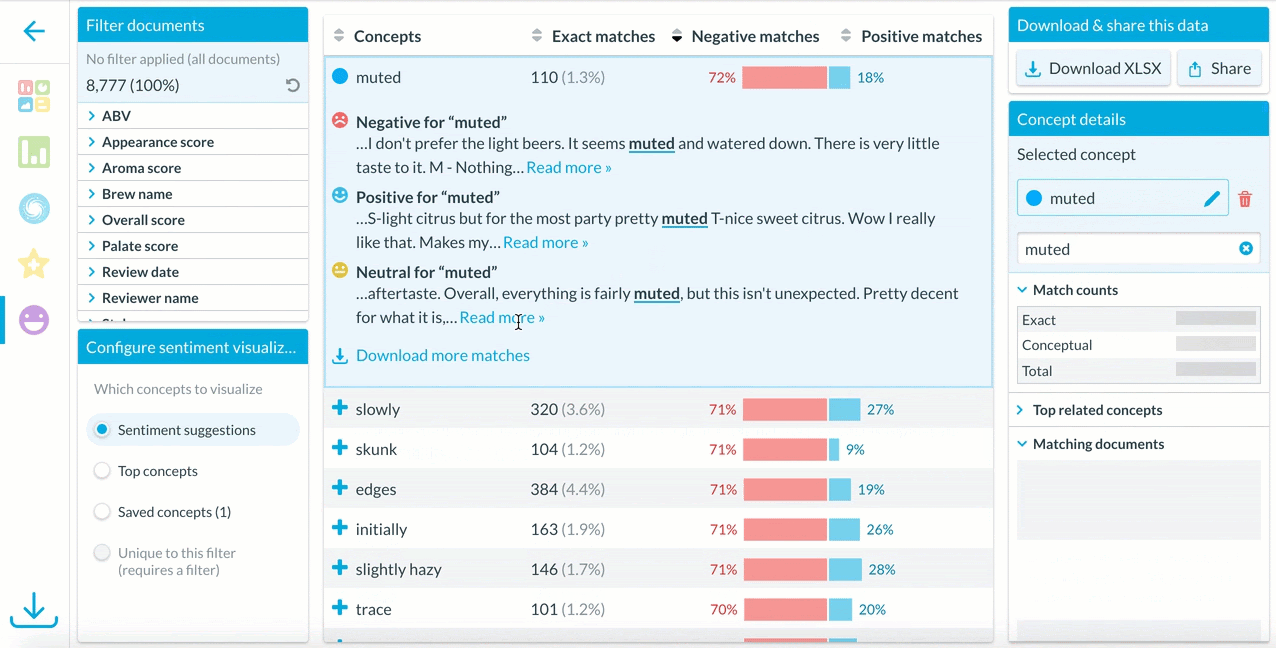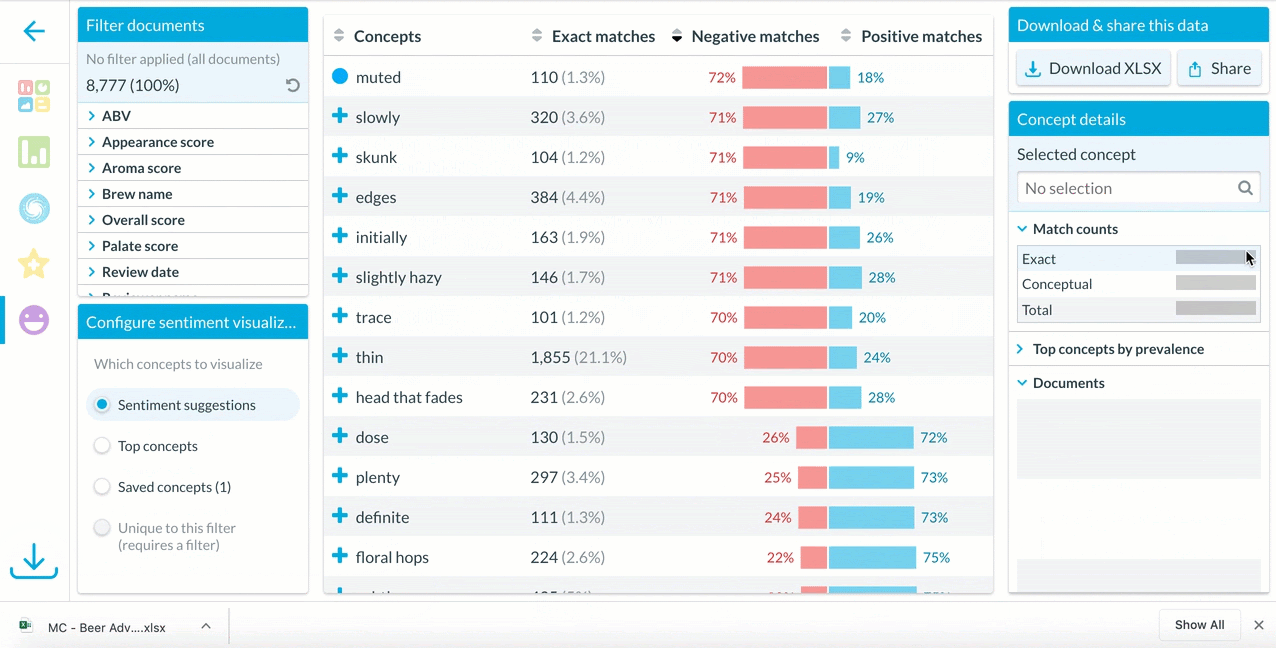
When users open a Daylight project, it automatically opens to the Highlights feature, which displays initial sentiment suggestions at the concept level.
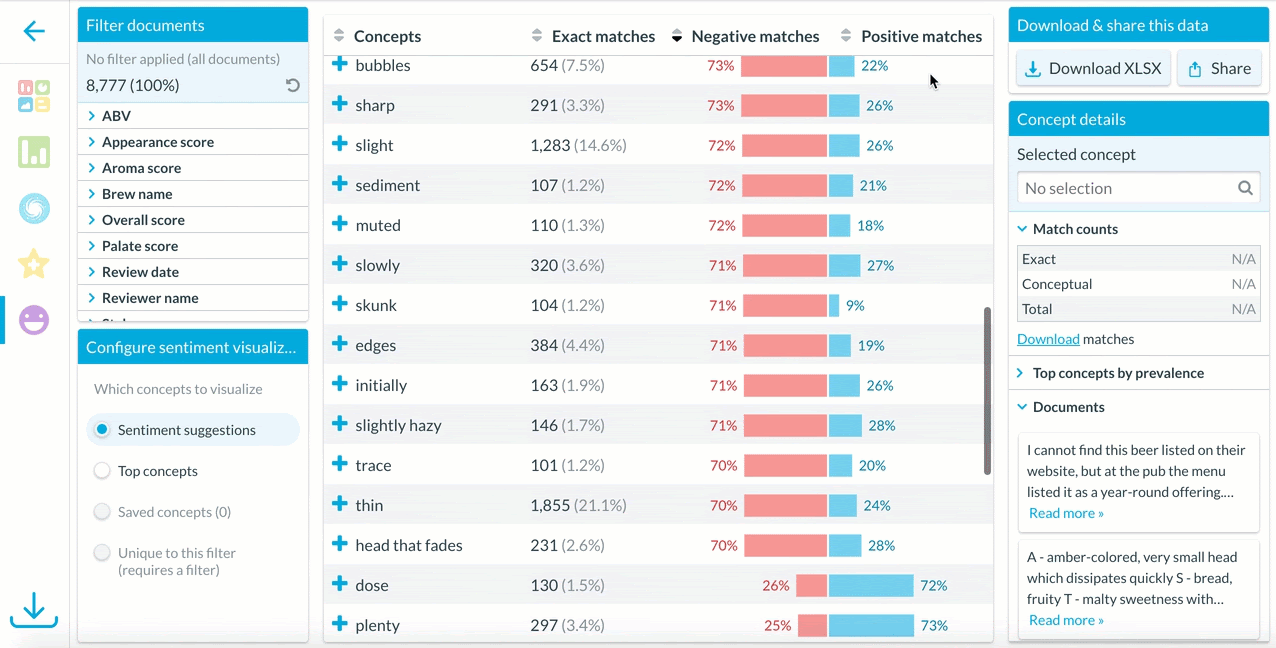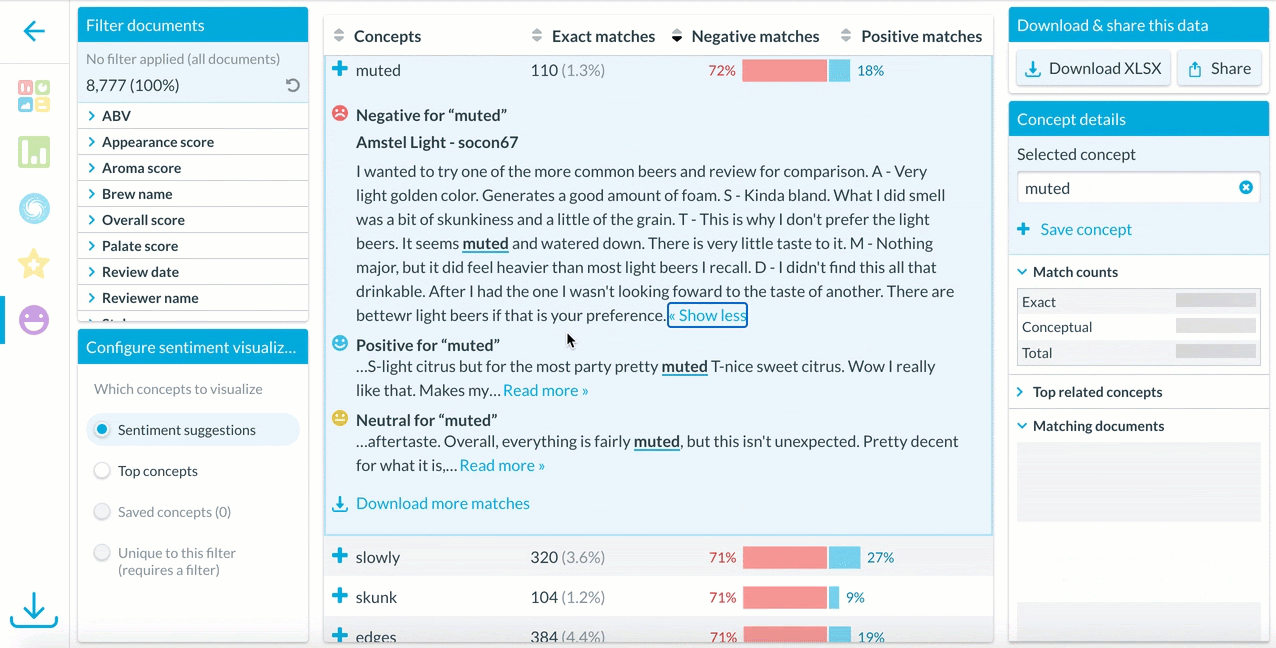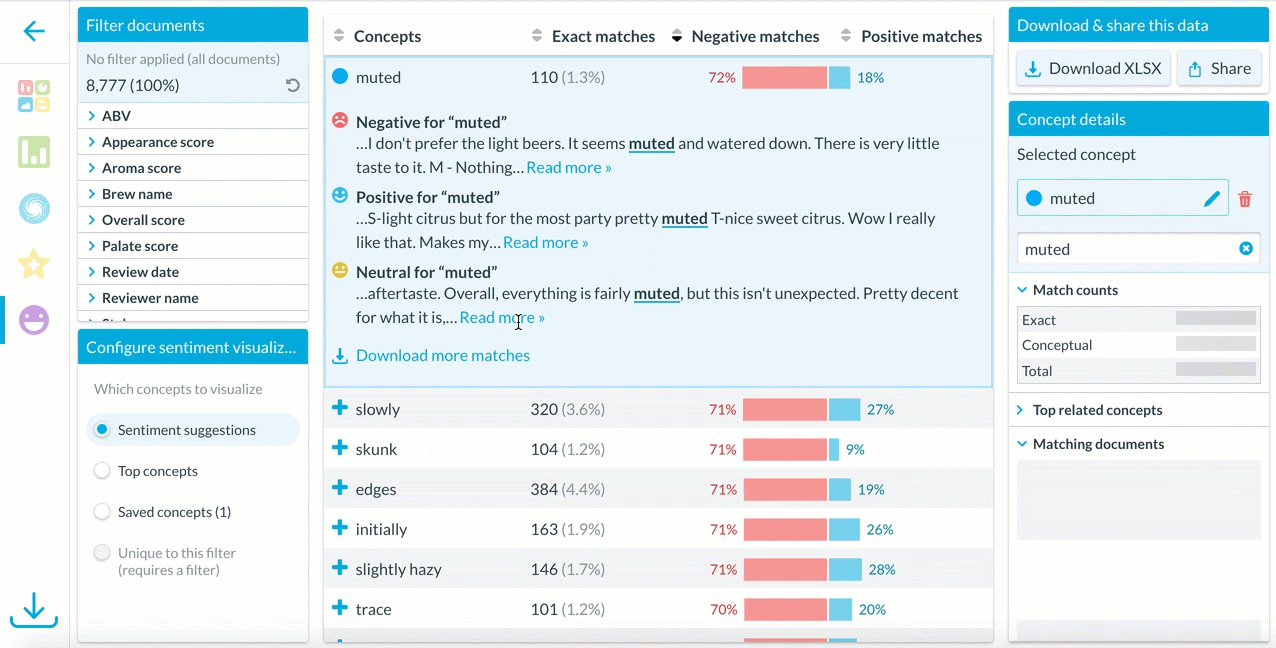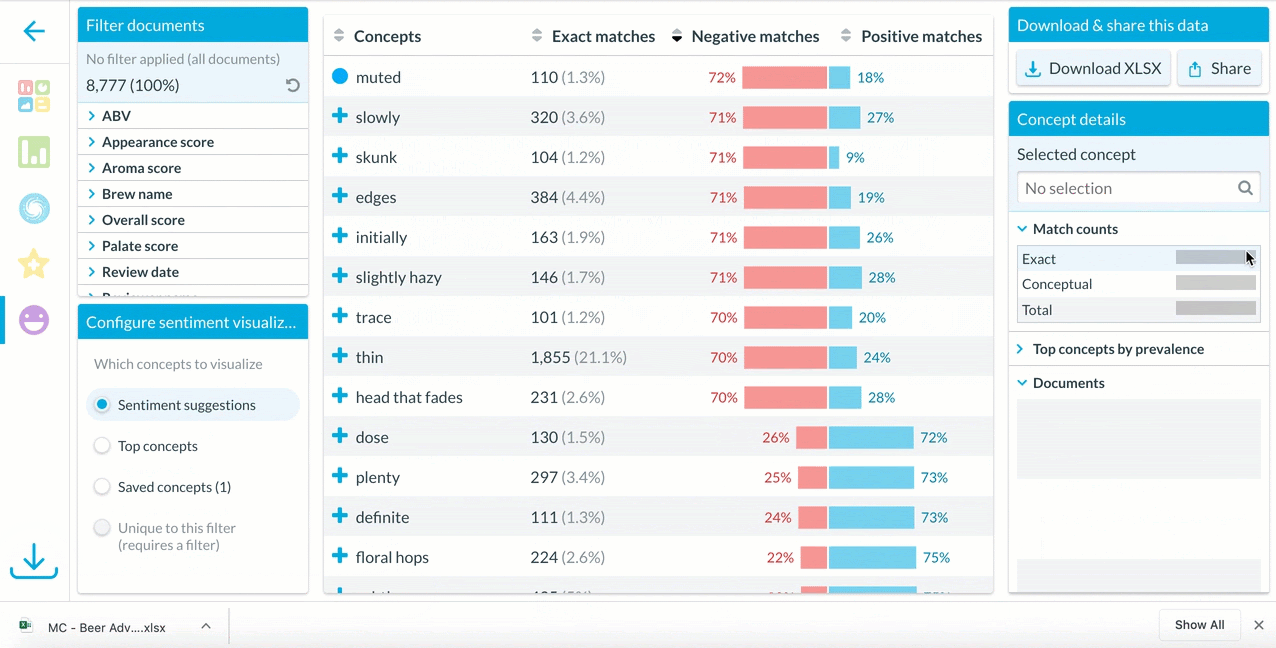
In the Sentiment feature, users can select different sets of concepts to view in the visualization – suggestions, top concepts, or saved concepts.

Then, users can use the sorting arrows above the concept list to sort alphabetically, by number of exact matches, percent negative, or percent positive.
Clicking on an interesting concept displays examples of how the concept is used in contexts with negative, positive, or neutral sentiment.

To explore more context around how a concept is used in a dataset, users can download all matches and explore a full list of how that concepts’ sentiment appears in every relevant document.
Say hello to cutting-edge sentiment
With this exciting release, Daylight includes sentiment technology that is on par with the industry gold standard, all as part of the app – still with no coding or ontologies required. We’re thrilled that Daylight can now detect buried sentiment and unlock true emotions about your offerings to solve problems or enhance positives. And the best news? Luminoso users don’t need a highly specialized skillset to dig deep into sentiment data. It’s as easy as uploading a spreadsheet and opening a project.
Ready to see Concept-Level Sentiment in action? Contact our team for a demo.












